XGBoost 모듈을 사용하면 XGBoost 모델 학습 및 예측을 단순화할 수 있습니다. XGBoost 모델을 학습할 때 여러 트리로 구성되며 개별 트리에서 정보를 얻고 싶을 수 있습니다. 예를 들어, (1) 주어진 개별 트리에서 개별 변수의 발생 빈도 또는 (2) 개별 트리의 예측 값을 알고 싶을 때가 있습니다. 이때 get_booster라는 타입을 사용하면 이 정보를 얻을 수 있다. 이 게시물에서는 get_booster로 얻은 개별 트리의 개별 변수의 빈도와 예측 값을 계산하는 방법을 살펴보겠습니다.
XGBoost의 개념과 XGBoost 모듈의 기본 사용법이 궁금하시다면 다음 포스트를 읽어주세요.
(XGBoost) XGBoost 모델 학습 (feat. XGBClassifier, XGBRegressor)
(XGBoost) XGBoost 모델 학습 (feat. XGBClassifier, XGBRegressor)
XGBoost 모듈은 XGBoost 모델 학습을 위한 다양하고 강력한 기능을 제공합니다. 이번 포스팅에서는 XGBoost로 XGBoost 모델을 학습하고 그 결과를 리뷰하는 방법을 알아보겠습니다. XGBoost 분
zephyrus1111.tistory.com
21. XGBoost에 대해 자세히 알아보기
21. XGBoost에 대해 자세히 알아보기
이번 포스트에서는 부스팅 시리즈의 떠오르는 샛별인 XGBoost에 대해 자세히 알아보겠습니다. 여기에서는 XGBoost의 개념과 알고리즘의 동작원리를 예제를 통해 고찰한다. – 목 차 – 1. XGBoost란?
zephyrus1111.tistory.com
get_booster 사용법
여기서는 문제를 회귀 문제와 분류 문제로 나눕니다. 문제마다 트리 구조가 다르기 때문입니다.
1) 회귀 문제
먼저 보스턴 주택 가격 데이터를 이용하여 XGBoost 회귀 모델을 학습한다.
import xgboost as xgb
from sklearn.datasets import load_boston
from xgboost.sklearn import XGBRegressor
boston = load_boston()
X, y = boston.data, boston.target
## XGBoost 학습
reg = XGBRegressor(
n_estimators=50, ## 붓스트랩 샘플 개수 또는 base_estimator 개수
max_depth=5, ## 개별 나무의 최대 깊이
gamma = 0, ## gamma
importance_type="gain", ## gain, weight, cover, total_gain, total_cover
reg_lambda = 1, ## tuning parameter of l2 penalty
random_state=100
).fit(X,y)
A. get_booster
회귀 모델이 학습되면 get_booster를 통해 개별 트리 정보를 얻을 수 있습니다. get_booster가 호출되면 booster 객체가 생성되고 feature_names 속성을 통해 변수 이름을 지정할 수 있습니다. 부스터 개체는 생성기의 한 유형이므로 부스터 개체이기도 한 목록에 트리를 묶어 개별 트리에 액세스할 수 있습니다.
reg_booster = reg.get_booster() ## Booster 객체 생성
reg_booster.feature_names = list(boston.feature_names) ## 변수명 지정
print('객체 타입 :', type(reg_booster))
individual_trees = list(reg_booster)
print('개별 트리 개수 :', len(individual_trees))
print('개별 트리 객체 타입 :', type(individual_trees(0)))
개별 트리의 수는 모델 훈련 중에 설정된 n_estimators와 동일합니다.

B. 개별 나무 정보 얻기
이제 개별 트리에서 여러 정보를 얻는 방법을 살펴보겠습니다.
(1) 가변 발행 빈도
get_score를 사용하면 각 개별 트리에서 분할할 때 변수의 발생 빈도를 계산할 수 있습니다. 이 경우 Important_type=”weight”를 설정해야 합니다(기본값).
tree = individual_trees(0) ## 첫 번째 트리
tree.get_score(importance_type="weight") ## 디폴트
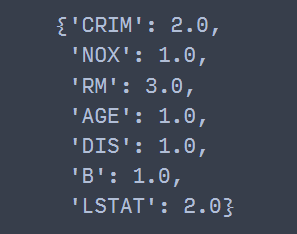
즉, 첫 번째 단일 트리에서 분할 중에 CRIM이 두 번, NOX가 한 번, RM이 세 번 나타났습니다.
(2) 변수 중요도
여기서 언급하는 중요도 변수는 일종의 MDI 기반 중요도 변수로 get_score에서 중요도 type=”gain”으로 설정할 수도 있다.
tree = individual_trees(0) ## 첫 번째 트리
tree.get_score(importance_type="gain") ## 디폴트
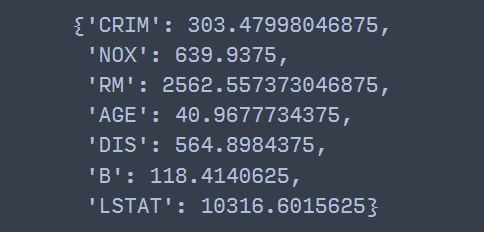
(3) 단일 트리 예측
예측을 사용하면 개별 트리에서 예측을 수행할 수 있습니다. 이 시점에서 데이터는 DMatrix로 변환되어야 하며 변수 이름이 있으면 변수 이름 배열이 feature_names 인수로 전달되어야 합니다.
tree = individual_trees(0) ## 첫 번째 트리
test_data = X(0).reshape(1, -1)
## 예측을 위해 예측 데이터를 Numpy array에서 DMatrix로 변환
test_data = xgb.DMatrix(test_data, feature_names=reg_booster.feature_names)
tree.predict(test_data) ## 예측

(4) 인간이 이해할 수 있는 트리로 변환
get_dump를 사용하여 사람이 읽을 수 있는 텍스트, json 또는 그래픽 형식으로 표시할 수 있습니다. get_dump의 출력은 요소가 주어진 형식의 개별 트리인 목록을 생성합니다. 여기서 json 형식을 사전 형식으로 변경해 보겠습니다.
import json
## with_stats True이면 gain과 같은 통계량 출력
dump = reg_booster.get_dump(dump_format="json", with_stats=True)
tree_dict = json.loads(dump(0)) ## 첫 번째 개별 트리
tree_dict
{'nodeid': 0,
'depth': 0,
'split': 'LSTAT',
'split_condition': 9.72500038,
'yes': 1,
'no': 2,
'missing': 1,
'gain': 18247.6094,
'cover': 506,
'children': ({'nodeid': 1,
'depth': 1,
'split': 'RM',
'split_condition': 6.94099998,
'yes': 3,
'no': 4,
'missing': 3,
'gain': 6860.23438,
'cover': 212,
'children': ({'nodeid': 3,
'depth': 2,
'split': 'DIS',
'split_condition': 1.48494995,
'yes': 7,
'no': 8,
'missing': 7,
'gain': 564.898438,
'cover': 142,
'children': ({'nodeid': 7, 'leaf': 11.8800001, 'cover': 4},
{'nodeid': 8,
'depth': 3,
'split': 'RM',
'split_condition': 6.54300022,
'yes': 15,
'no': 16,
'missing': 15,
'gain': 113.882813,
'cover': 138,
'children': ({'nodeid': 15, 'leaf': 6.64261389, 'cover': 87},
{'nodeid': 16, 'leaf': 8.01750088, 'cover': 51})})},
{'nodeid': 4,
'depth': 2,
'split': 'RM',
'split_condition': 7.43700027,
'yes': 9,
'no': 10,
'missing': 9,
'gain': 713.554688,
'cover': 70,
'children': ({'nodeid': 9, 'leaf': 9.67683029, 'cover': 40},
{'nodeid': 10,
'depth': 3,
'split': 'CRIM',
'split_condition': 2.74223518,
'yes': 17,
'no': 18,
'missing': 17,
'gain': 260.210938,
'cover': 30,
'children': ({'nodeid': 17, 'leaf': 13.165, 'cover': 29},
{'nodeid': 18, 'leaf': 3.21000004, 'cover': 1})})})},
{'nodeid': 2,
'depth': 1,
'split': 'LSTAT',
'split_condition': 16.0849991,
'yes': 5,
'no': 6,
'missing': 5,
'gain': 2385.59375,
'cover': 294,
'children': ({'nodeid': 5,
'depth': 2,
'split': 'B',
'split_condition': 116.024994,
'yes': 11,
'no': 12,
'missing': 11,
'gain': 118.414063,
'cover': 150,
'children': ({'nodeid': 11, 'leaf': 3.54750013, 'cover': 7},
{'nodeid': 12, 'leaf': 5.99104166, 'cover': 143})},
{'nodeid': 6,
'depth': 2,
'split': 'NOX',
'split_condition': 0.603000045,
'yes': 13,
'no': 14,
'missing': 13,
'gain': 639.9375,
'cover': 144,
'children': ({'nodeid': 13, 'leaf': 5.06040001, 'cover': 49},
{'nodeid': 14,
'depth': 3,
'split': 'CRIM',
'split_condition': 11.3691502,
'yes': 19,
'no': 20,
'missing': 19,
'gain': 346.749023,
'cover': 95,
'children': ({'nodeid': 19,
'depth': 4,
'split': 'AGE',
'split_condition': 77.9499969,
'yes': 21,
'no': 22,
'missing': 21,
'gain': 40.9677734,
'cover': 63,
'children': ({'nodeid': 21, 'leaf': 0.870000064, 'cover': 1},
{'nodeid': 22, 'leaf': 4.03857136, 'cover': 62})},
{'nodeid': 20, 'leaf': 2.5854547, 'cover': 32})})})})}
코드를 실행하면 출력이 (적어도) 사람이 이해하기 쉬운 형태로 되어 있음을 알 수 있습니다. 위 결과에서 각 속성의 의미는 다음과 같다.
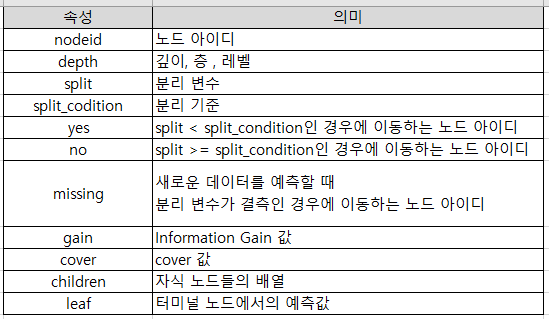
사전으로 구성된 개별 트리를 사용하여 다양한 발생 빈도 및 예측 값을 계산할 수 있습니다. 다음 함수는 사전 형태의 트리에 대한 변수의 발생 빈도를 계산합니다.
rom collections import Counter
def get_features_ocurrence(dict_data, res):
if 'children' not in dict_data and dict_data('nodeid') == 0:
## Root 노드만 있는 경우 스플릿 변수를 추가한 뒤 리턴
res.append(dict_data('split'))
return Counter(res)
elif 'leaf' in dict_data:
return
else:
res.append(dict_data('split'))
for dict_elem in dict_data('children'):
get_features_ocurrence(dict_elem, res)
return Counter(res)
위의 함수를 사용하여 첫 번째 트리에서 변수의 발생 빈도를 고려하십시오.
## 개별 트리에서의 변수 발생 빈도
get_features_ocurrence(tree_dict, ())

코드를 실행할 때 get_score를 사용하여 이전 방법과 동일한 결과를 얻을 수 있습니다. 이번에는 사전 형태의 트리를 이용하여 예측을 해보겠습니다. 다음 함수는 예측할 데이터와 사전 형태의 트리, 변수 이름을 입력받아 예측값을 계산합니다.
def predict_from_individual_tree(data, dict_data, feature_names):
if 'leaf' in dict_data:
return dict_data('leaf')
else:
split_feature = dict_data('split') ## 분리 변수
feature_idx = feature_names.index(split_feature) ## 변수 인덱스
split_value = dict_data('split_condition') ## 분리 기준
flag = 'missing'
if data(feature_idx) < split_value:
flag = 'yes'
else:
flag = 'no'
child_node_id = dict_data(flag)
children_node = (x for x in dict_data('children') if x('nodeid') == child_node_id)(0)
return predict_from_individual_tree(data, children_node, feature_names)
data = X(0)
predict_from_individual_tree(data, tree_dict, reg_booster.feature_names)

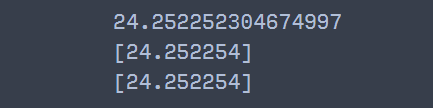
위의 코드를 실행해보면 get_booster로 예측한 값과 같은 것을 확인할 수 있습니다. 개별 트리를 사용하여 XGBoost 모델의 예측값을 얻으려면 각 개별 트리의 예측값을 모두 참고로 합산한 다음 모델 학습 중에 설정한 base_score를 더해야 합니다. 실제로 단일 트리에서 계산한 예측값과 XGBoost 모델에서 계산한 예측값이 같다는 것을 알 수 있습니다(단, 소수점은 약간의 차이가 있긴 하지만요 ㅎㅎ).
from collections import Counter
import numpy as np
data = X(0)
feature_names = reg_booster.feature_names ## booster 객체의 변수명 속성
predict_res = ()
count_dict = Counter()
for d in dump:
dict_data = json.loads(d)
predict_val = predict_from_individual_tree(data, dict_data, feature_names)
predict_res.append(predict_val)
base_score = reg.get_params()('base_score')
print(np.sum(predict_res)+base_score) ## 개별 트리로부터 얻은 예측값
print(reg.predict(data.reshape(1, -1))) ## XGBoost 예측값
data_dm = xgb.DMatrix(data.reshape(1, -1), feature_names=feature_names)
print(reg_booster.predict(data_dm)) ## Booster를 이용한 XGBoost 예측값
2) 분류 문제
이번에는 분류 문제를 위해 각 XGBoost 트리에 대한 정보를 꺼내보겠습니다. 먼저 Iris 데이터를 사용하여 XGBoost 모델을 학습합니다.
from sklearn.datasets import load_iris
from xgboost.sklearn import XGBClassifier
iris = load_iris()
X, y = iris.data, iris.target
clf = XGBClassifier(
n_estimators=50, ## 붓스트랩 샘플 개수 또는 base_estimator 개수
max_depth=5, ## 개별 나무의 최대 깊이
gamma = 0, ## gamma
importance_type="gain", ## gain, weight, cover, total_gain, total_cover
reg_lambda = 1, ## tuning parameter of l2 penalty
random_state=100,
).fit(X,y)
A. get_booster
get_booster의 사용은 회귀 문제에서와 동일합니다.
clf_booster = clf.get_booster() ## Booster 객체 생성
clf_booster.feature_names = list(iris.feature_names) ## 변수명 지정
print('객체 타입 :', type(clf_booster))
individual_trees = list(clf_booster)
print('개별 트리 개수 :', len(individual_trees))
print('개별 트리 객체 타입 :', type(individual_trees(0)))
B. 개별 나무 정보 얻기
개별 트리에서 여러 정보를 얻는 방법을 살펴보겠습니다.
(1) 가변 발행 빈도
get_score 메서드에서 Important_type=”weight”를 설정하면 단일 트리에서 변수의 발생 빈도를 계산할 수 있습니다.
tree = individual_trees(0)
tree.get_score(importance_type="weight")

(2) 변수 중요도
변수의 중요도를 얻으려면 get_score에 Important_type=”gain”을 지정하십시오.
tree = individual_trees(0)
tree.get_score(importance_type="gain")

(3) 단일 트리 예측
예측을 사용하면 개별 트리에서 각 클래스에 대한 확률 예측 값을 얻을 수 있습니다. 홍채 데이터에는 3개의 클래스가 있으므로 3개의 확률 값을 얻습니다.
tree = individual_trees(0) ## 첫 번째 트리
test_data = X(0).reshape(1, -1)
## 예측을 위해 예측 데이터를 Numpy array에서 DMatrix로 변환
test_data_dm = xgb.DMatrix(test_data, feature_names=clf_booster.feature_names)
tree.predict(test_data_dm) ## 예측

예측 클래스는 확률 예측값 중 가장 큰 값에 해당하는 클래스로 선택된다.
(4) 인간이 이해할 수 있는 트리로 변환
get_dump를 사용하여 사람이 읽을 수 있는 형식으로 트리를 얻을 수 있습니다.
dump = clf_booster.get_dump(dump_format="json")
print(dump(0)) ## 첫 번째 개별 트리

회귀 문제와 달리 get_dump가 반환하는 개별 트리의 총 개수는 150개입니다.
print('개별 트리 개수 :', len(dump))

XGBoost 모델을 학습할 때 설정한 n_estimators=50에 클래스 개수인 3을 곱한 값이다. 그렇게 만들어진 이유는 개별 나무가 일대일 모양을 갖기 때문입니다. 이 경우 get_booster의 첫 번째 단일 트리는 get_dump의 처음 3개 트리(클래스 수)와 동일합니다.
아래 코드와 같이 처음 3개의 트리 각각에 대해 변수의 발생빈도를 계산해보면 앞선 계산과 동일함을 알 수 있다.
num_class = len(np.unique(y))
count_dict = Counter()
for d in dump(:num_class):
dict_data = json.loads(d)
count_dict += get_features_ocurrence(dict_data, ())
count_dict

다음 코드는 각 트리에서 XGBoost 분류 모델의 예측 클래스를 가져오는 과정입니다. 이때, 0으로 분류된 클래스를 학습하는 개별 트리는 dump(0), dump(3), …이고, 1로 분류된 클래스를 학습하는 개별 트리는 dump(1), dump(2), … 오전.
from scipy.special import expit as sigmoid
clf_booster = clf.get_booster()
clf_booster.feature_names = iris.feature_names ## 붓꽃 데이터 변수명 설정
dump = clf_booster.get_dump(dump_format="json")
feature_names = clf_booster.feature_names
labels = np.unique(y)
predict_labels = ()
for data in X:
predict_results = ()
for l in labels:
predict_values = ()
for d in dump(l::len(labels)):
dict_data = json.loads(d)
predict_value = predict_from_individual_tree(data, dict_data, feature_names)
predict_values.append(predict_value)
predict_results.append(predict_values)
predict_results = np.c_(predict_results).T
summary_results = sigmoid(np.sum(predict_results, axis=0)+0.5) ## 로그 오즈에 시그모이드 함수 적용
predict_labels.append(np.argmax(summary_results)) ## 라벨 예측
predict_labels = np.array(predict_labels)

이는 실제 XGBoost로 학습한 예측 결과와 동일합니다.
np.all(clf.predict(X) == predict_labels) ## 두 어레이는 같은가?
